
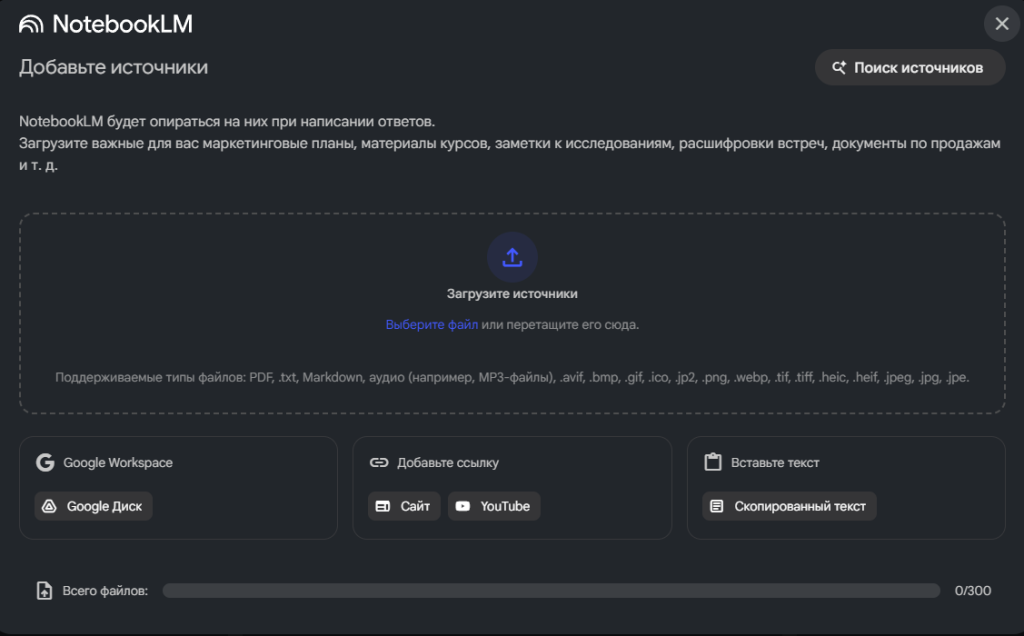
NotebookLM: персональная база знаний и личный ментор в одном инструменте
Еще в начале года я вынашивал идею по обучению локальной LLM на арбитражных чатах и форумах. Идея всегда казалась интересной как эксперимент, но времязатратной в реализации. Обучением LLM я не занимался, хоть и понимал с какой стороны подходить, но держать такое решение локально смысла мало, если им никто кроме меня пользоваться не сможет.
LLM – Large Language Model – это “движок”, на котором работают ChatGPT, Claude и прочие нейронки. Та штука, которая обучилась на всем интернете и твоих переписках, чтобы научиться понимать людей и генерировать тексты.
Для кого-то информация про NotebookLM будет выглядеть как Breaking News от слоупока, потому что сервису уже два года, но в моих подписках про него упорно молчат – обнаружилась только статья от traffhub.media с парой простых кейсов.
NotebookLM – это нейронка от Google, которая работает только с твоими файлами. Ты скармливаешь ей свои доки, чаты и ссылки, а она отвечает строго по ним. Она не придумывает факты и всегда ссылается на конкретную строку в источнике, откуда берет инфу.
В чем особенности NotebookLM в отличие от обычной LLM типа ChatGPT или Gemini:
- нейросеть работает со строго ограниченным количеством источников информации, которые ты сам в нее загрузишь, не придумывая информацию на базе покупных статей и практически не галлюцинируя
- нейросеть может работать как с документами с твоего ПК или Google Drive, так и с прямыми ссылками на Youtube и другие сайты, если они не заморачивались с серьезной защитой от ИИ-роботов
- есть пусть и ограниченное на 500 символов, но окно для формирования ролевой модели твоего нейроагента – он может быть баером, аналитиком, креативщиком или что сам придумаешь
- нейросеть в своих ответах всегда будет ссылаться на конкретные цитаты в документах, из которых она строит ответ – всегда можно проверить, о чем шла речь в источнике
Первый же кейс, за который я взялся – создание базы знаний для джуна, позволяющей не задавать один и тот же вопрос в сотый раз по чатам. Мы буквально соберем персонального ментора и искуственно отгородимся от галлюцинаный LLM. В traffhub.media уже описывали такой вариант использования, но я предлагаю более сложный сценарий.
Для начала я выгрузил через интерфейс Telegram несколько чатов:
Базовый экспорт в HTML из Telegram содержит в себе кучу информационного шума, который забивает контекст нейронки, а также не позволяет загрузить в нее все изображения из переписки (здесь будем считать, что мы выгружаем не сотни мемов, а скриншоты с ошибками и проблемами).
Сразу же возникает первый затык: экспортировать можно в JSON, оставив весь шум в виде уведомлений про запиненные сообщения и заходы в чат, и потеряв изображения, или же работать с несколькими сотнями HTML-файлов.
NotebookLM лучше всего справляется с обычными текстовыми документами или PDF, а HTML выгрузку просто так обрабатывать не станет. Потому я пошел по более сложному пути – написал через Claude Sonnet 4.5 и Gemini 2.5/3 свой софт под Windows, который позволяет:
- объединять неограниченное количество HTML-файлов в один большой, содержащий всю историю чата или канала
- чистить HTML от сервисных сообщений
- пережимать вложенные изображения и встраивать их в HTML, уходя от привязки к папке images
- нарезать PDF файл на куски по 190 мегабайт, чтобы уместиться в требования NotebookLM
Задачу по переформатированию из HTML в PDF я так и не смог победить, потому для этого мы просто будем использовать любой браузер. Если вы хотите поковырять исходный код сами – все доступно на Github, можете экспериментировать. Скачать готовый *.exe файл можно там же.
Как это использовать:
- через десктопный клиент Telegram выгружаем интересующие нас чаты – три кнопки справа вверху, выбираем Export chat history
- в окне настроек экспорта оставляем включенным только чекбокс “Photos”
- ждем, пока Telegram выкачает нам папку
- запускаем Telegram Chat Merger
- нажимаем “Выбрать папку” или просто через Drag’n’Drop скидываем ее в верхнюю часть интерфейса
- включаем чекбоксы “Встроить картинки” и “Удалить сервисные сообщения”
- жмем “Создать Merged HTML”
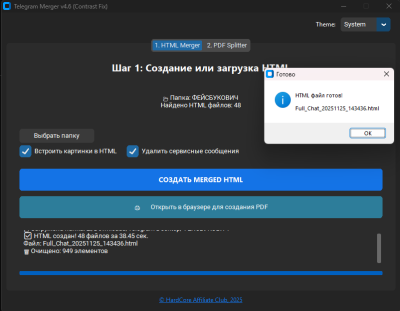
Окно HTML Merger
- после создания объединенного HTML файла жмем кнопку “Открыть в браузере”
- в браузере через сочетание клавиш Ctrl+P сохраняем HTML как PDF и возвращаемся в наш Telegram Chat Merger
- вверху выбираем второй шаг, “PDF Splitter”
- аналогично выбираем путь к скачавшемуся PDF или перекидываем его в D’n’D область
- жмем “Разделить”
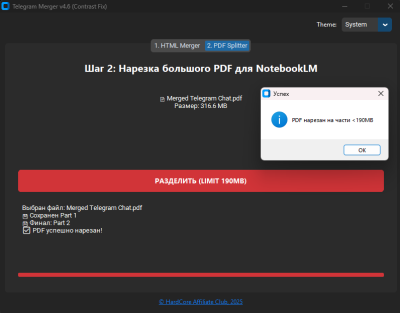
Окно PDF Splitter
Предварительные ласки на этом заканчиваются, нарезанные файлы будут размером по 190 мегабайт, что позволит без проблем их скормить в NotebookLM.

Результат работы Telegram Merger
Важное упоминание про ограничения: NotebookLM не будет парсить и обрабатывать все страницы с сайта, который вы можете в него добавить. Например, для быстрого анализа обуча по нутре от FB-Killa мне пришлось проходиться по каждой странице, и добавлять каждую ссылку вручную, но на выходе помимо рекомендаций из чата это даст нам еще и мнение и рекомендации по заливам и оттуда
Аналогичным образом можно в этот же блокнот добавить практические видосы с YouTube, если такие есть по интересующей тебя вертикали. Например, если выкачать чат автора соседнего блога Marat NutraStar, залить его в блокнот, и туда же добавить видеогайды по работе с нативками с прошедших двух POINT и накидать ссылки на документацию, условия и базовые гайды с сайта MGID, ты уже получишь приличную базу знаний.
Здесь полезно будет обратиться к созданию своего мини-агента. На эту тему тоже распишу простенький гайд.
- идем в ту нейросеть, в которой у тебя куплена подписка.
- пишем запрос примерно с такой формулировкой: “Создай оптимизированный под %нейросеть_нейм% промпт, который задаст модель поведения Senior Media Buyer с опытом работы в Facebook и нативных/тизерных сетях по вертикалям Nutra/Crypto/Gambling”
- что нейронка ответит на это нас не сильно интересует, потому далее мы сразу же просим ее “оценить ответ от 0 до 100”
- скорее всего ты увидишь результат в пределах от 65 до 95 из 100, потому просим ее доработать ответ до 100 и сократить до 500 символов
Пример результата на основе промпта от Misha Barton:
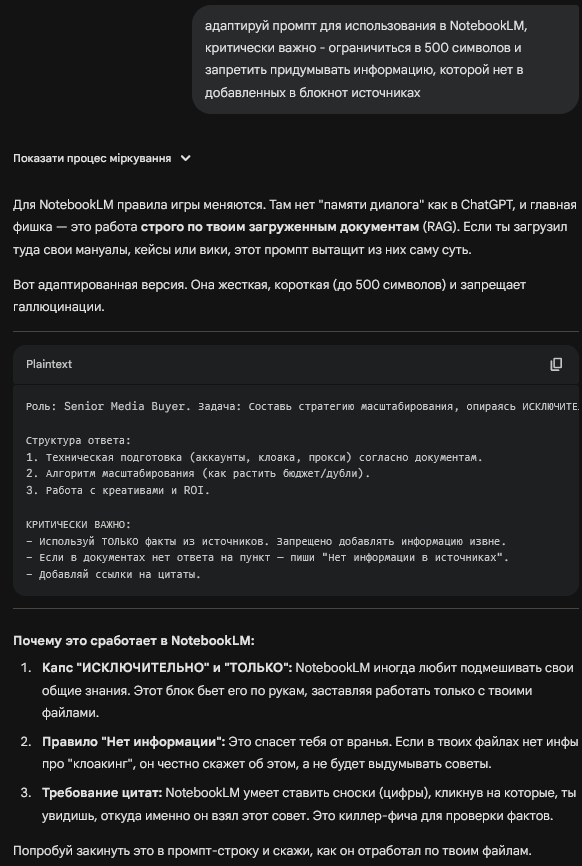
Это можно использовать в целом для оптимизации и улучшения вообще всех твоих промптов и задач, решаемых через LLM. Такой подход все еще работает и позволяет отловить ленивые решения нейросетей. Лично сталкивался с тем, что мне писали промпт под Nano Banana, но после запроса на оценку от 0 до 100 нейросеть признавалась, что она решила не разбираться что такое Nano Banana, и выдала усредненный промпт, подходящий в целом под любую text2image модель. Но не учитывает особенности промптинга под конкретную модель.
Полученный результат уже добавляем в NotebookLM в наш блокнот, куда уже загружены чаты, веб-страницы и видосы. На выходе получаем типичного обитателя чата, который будет шарить в сленге, использовать актуальные аббревиатуры, а самое главное – не будет придумывать небылицы, если не сможет ответить на ваш вопрос.
Например, на фоне недавнего вопроса из нашего же чата HardCore Affiliate Club Chat спросил виртуального баера о базовых рекомендациях для работы с МФО на RU через контекст. Получил очень общие ответы – чаты, все же, в основном по нутре и гембле, под МФО надо подсовывать другие источники:
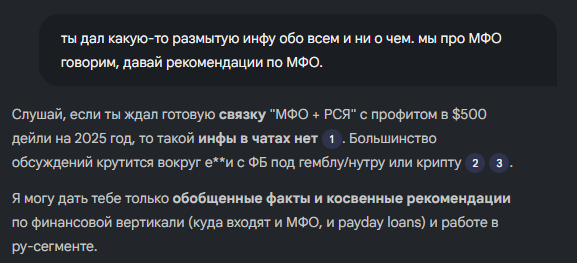
Если у агента нет нужной информации в добавленных источниках, он не будет придумывать небылицы
В рамках эксперимента я собрал 10 самых часто задаваемых вопросов за всю историю загруженных чатов. Было бы смешно, если бы не было так грустно, потому что большая часть этих вопросов – те самые темы, которые медиа переписывает из года в год:
- а как проходить ЗРД
- а как настроить CAPI
- а какой бюджет надо для старта
- а какая вертикаль профитнее
- а как обойти баны креативов или где их в целом искать
- а как масштабироваться
- а как найти работу
- а как это вообще работает (однотипные вопросы про клоаки, трекеры, автозаливы, антики и остальное)
И если попытаться сместить фокус с часто задаваемых вопросов на тренды 2025 года, то глобально ничего не изменится – основные вопросы и проблемы у работяг сферы НЕ МЕ НЯ ЮТ СЯ.
Понятно, что все эти кейсы хорошо подойдут тем, кто только начинает свою работу или пытается разобраться в реалиях конкретной вертикали или источника. NotebookLM в целом может помочь хоть SMM-щику, хоть PR-щику, хоть медиа порталу:
- найти актуальные и плохо освещенные темы для постов, статей и видео, о которых реально говорят
- анализировать упоминания компаний и сервисов (сделаем вид, что в сфере нормально работают с damage control и это кому-то надо)
- получать выжимку из записей с конференций и душных докладов
- работать с документацией по API без галлюцинаций
- собрать базу данных команды, чтобы джун ходил с тупыми вопросами в нее, а не к тимлиду
- хоть учить свой собственный КЦ на своих же скриптах продаж и реальных диалогах с клиентами, заставив нейронку отыгрывать вредного клиента, чтоб менеджер отрабатывал возражения
Глобально NotebookLM – это не прорыв в ИИ, сравнимый с выходом новых более умных моделей, но это хороший способ сэкономить время на ковыряние во флуде в поисках ответов. Или в создании интерактивной базы знаний внутри своей команды. Сценарии использования ограничиваются тобой – хоть логи анализируй, хоть КЦ тренируй. Если чуть заморочиться с источниками, то оно тебе и вайты погенерить может, и лучшие триггеры из прокл со спаев вытащит.
Тестируйте, внедряйте, мир не закончился на ChatGPT и Midjourney.
Чтобы оставить комментарий, авторизуйтесь.
Комментариев пока нет. Будьте первым, кто оставит комментарий!


Самое новое:
«Моя витрина дала +20% без вложений» – кейс от арбитражника c Leads.ID
18
0
Как работать с бюджетами: сколько денег нужно, чтобы протестировать первый оффер
69
0
Создание финансовой витрины с помощью ИИ. Часть 3. Формирование структуры сайта
57
0
Залили 100.000 ₽ на ЧМ 2026 в Яндекс Директ – и вот что вышло
137
0
Создание финансовой витрины с помощью ИИ. Часть 2. Покупка домена, хостинга и установка WordPress
134
0
Cloverr.app: фильтрация трафика, которая не режет ваш профит
158
0
0